
Engineering · 6 min
Oltre i Chatbot: Architettura di un Sistema Multi-Agente per la Validazione Industriale (Il caso MachinaCheck)
Scopri l'architettura di un sistema multi-agente per la validazione industriale. Analizziamo le scelte ingegneristiche per creare workflow agentici robusti.
Un sistema multi-agente supera nettamente un LLM monolitico quando i task richiedono specializzazione, fault isolation e debugging granulare. Mentre un singolo modello tenta di gestire tutte le responsabilità in un'unica forward pass, un'architettura basata su agenti scompone il problema in step logici e assegna a ogni agente un ruolo specifico con tool dedicati. Il risultato: riducete gli errori composti, migliorate la traceabilità, e rendete il sistema manutenibile in produzione. MachinaCheck, un sistema per la validazione industriale di disegni CAD e la generazione di G-code per macchine CNC, dimostra concretamente come questa decomposizione porti a risultati superiori rispetto a un approccio monolitico.
Perché un Sistema Multi-Agente è superiore a un LLM Monolitico per task complessi?
Un LLM monolitico ha un limite intrinseco: deve mantenere coerenza su lunghe catene di ragionamento in una singola forward pass. Quando il task cresce in complessità — comprensione visuale, validazione contro vincoli fisici, generazione di codice specifico per macchina — il modello accumula errori e diventa difficile capire dove il ragionamento si è rotto.
Confronto visivo tra un'architettura AI monolitica e una modulare a più agenti.
L'approccio modulare segue il principio di singola responsabilità applicato all'AI. Ogni agente:
- Ha un obiettivo stretto e misurabile
- Usa tool specifici per il proprio dominio (API, database, parser)
- Comunica il suo output in un formato strutturato (JSON, YAML)
- Può essere testato, versioned e sostituito indipendentemente
In pratica, questo significa che se l'agente responsabile della validazione geometrica sbaglia, non contamina la generazione del codice. Il difetto rimane isolato e il team può correggere quel singolo agente senza toccare il resto dell'architettura.
Un'architettura modulare offre anche vantaggi concreti in produzione:
- Specializzazione: ogni agente può usare il modello piu adatto (un 8B per parsing, un 70B per reasoning complesso) e decidere localmente quali tool usare
- Manutenibilità: il prompt e i tool di un agente vivono in un namespace isolato; cambiamenti non propagano effetti laterali
- Fault tolerance: se un agente fallisce, una strategia di fallback (retry, escalation, fallback a default) contiene il danno
Come Progettare un Agentic Workflow: l'Architettura di MachinaCheck
MachinaCheck decompone il problema in quattro agenti specializzati, ognuno con un ruolo chiaro. Questo non e casuale: la scomposizione del problema guida direttamente la progettazione degli agenti.
Il flusso e:
- Agente Charter: riceve il file CAD e il brief dell'operatore. Estrae specifica tecnica, vincoli, e definisce il piano d'azione
- Agente Checker: esamina il disegno tramite computer vision, valida geometria, tolleranze e fattibilita manufatturiera contro un database di vincoli
- Agente Tooler: seleziona utensili e parametri di taglio ottimali per i materiali e le geometrie identificate dal Checker
- Agente Coder: genera il G-code finale per la macchina CNC sulla base dei parametri stabiliti dagli agenti precedenti
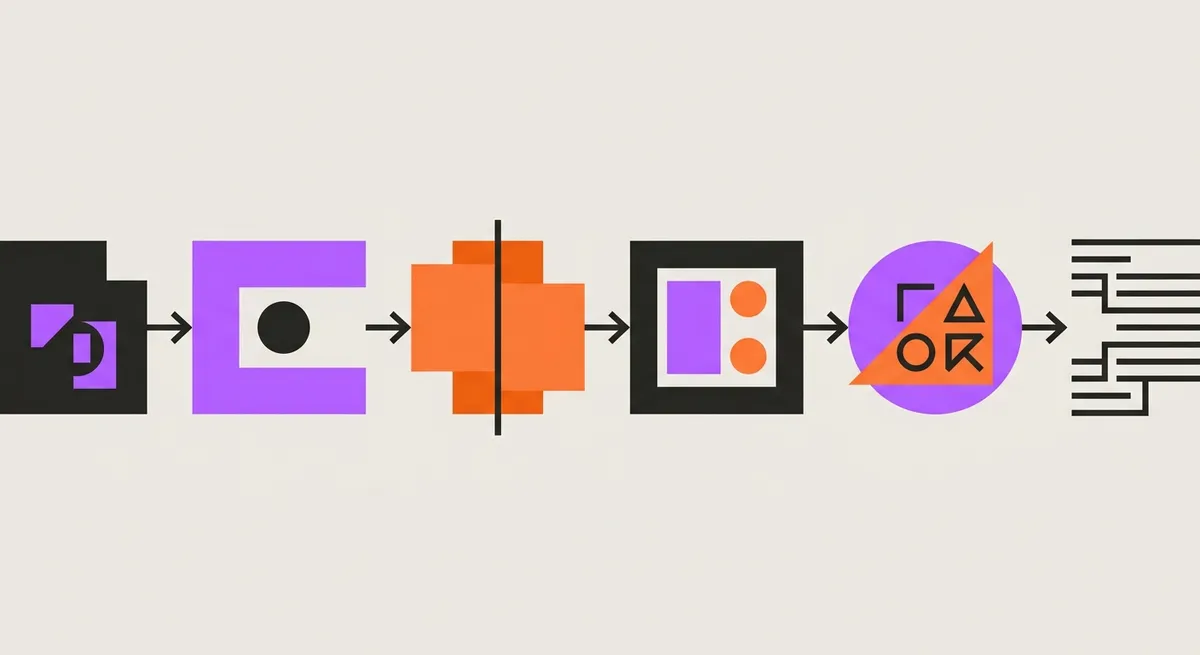
Diagramma del flusso di lavoro di un sistema multi-agente per la validazione industriale.
Ecco come avviene l'orchestrazione:
input: file_cad, operator_brief
├─ Charter
│ ├─ prompt: "Analizza il brief e il CAD. Estrai spec tecnica e lista vincoli"
│ ├─ tools: cad_parser, spec_extractor
│ └─ output: { specifications, constraints, action_plan }
├─ Checker
│ ├─ prompt: "Valida il disegno contro i vincoli. Identifici geometrie a rischio"
│ ├─ tools: cv_analyzer, geometry_validator, constraint_checker
│ └─ output: { validation_report, flagged_features, feasibility_score }
├─ Tooler
│ ├─ prompt: "Seleziona utensili e parametri di taglio per le geometrie date"
│ ├─ tools: tool_database, cutting_param_calculator
│ └─ output: { tool_selection, cutting_params, estimated_time }
└─ Coder
├─ prompt: "Genera G-code ottimale per i parametri stabiliti"
├─ tools: gcode_generator, simulation_validator
└─ output: { gcode, simulation_preview, execution_estimate }
La logica di comunicazione tra agenti e semplice ma strutturata:
- Output di un agente = input del successivo
- Se il Checker restituisce
feasibility_score < 0.7, il workflow escalate all'operatore invece di procedere - Ogni agente ha un timeout e un fallback: se l'analisi CV del Checker non converge, un'euristica conservativa sostituisce il risultato
Questa decomposizione emerge dalle caratteristiche stesse del problema. La validazione geometrica (Checker) e un compito visuale che beneficia di model e tool specifici; la selezione utensili (Tooler) e domain knowledge puro; la generazione di codice (Coder) richiede precisione sintattica. Farle tutte in un'unica forward pass porterebbe a conflitti di attenzione e a degradazione della qualita.
Generazione di Codice e Analisi Visuale con Agenti AI Specializzati
L'agente Checker dimostra come la computer vision aumenti le capacita di un LLM. Invece di chiedere al modello di "analizzare il CAD come testo", lo strumento cv_analyzer converte il disegno in feature vector (spigoli, curve, gradienti, aree critiche) che il modello riceve come input strutturato.
Questo approccio risolve un limite reale: gli LLM sono deboli nell'analisi spaziale precisa su immagini tecniche. Una CNN addestrata su disegni CAD di parti meccaniche estrae direttamente:
- Geometrie critiche: fori, smussi, spallamenti
- Tolleranze annotate: ±0.05 mm su una superficie di appoggio
- Zone a rischio di rottura: spigoli acuti che la macchina farebbe fatica a mantenere
L'LLM riceve questo report strutturato e applica il suo ragionamento di dominio per decidere se il disegno e fattibile. Se trova una geometria critica con tolleranza stretta e una zona a rischio, puo chiedere al tool geometry_validator di simulare l'operazione di taglio e valutare il risultato.
L'agente Coder affronta un problema opposto: generazione di codice sintattico. Il G-code non e prosa; e un linguaggio procedurale con regole rigorose. Una semplice allucinazione (una coordinata sbagliata di una cifra, un comando malformato) rende il codice inutilizzabile.
La strategia:
- Il modello genera il primo draft di G-code usando in-context learning (esempi di pattern corretti nel prompt)
- Un tool linter e validator effettua parsing sintattico e simula l'esecuzione
- Se ci sono errori, il tool restituisce un report di debug che il modello usa per correggere il draft
Questo ciclo iterativo e rapido: il modello non erra a caso, ha un feedback concreto. In genere convergono in 2-3 iterazioni.
Il valore della specializzazione sta nella riduzione della complessità cognitiva per ogni agente. Il Checker non deve sapere come generare G-code; il Coder non deve capire di geometria. Ognuno diventa molto bravo nel suo ambito.
Dalla Prototipazione alla Produzione: Sfide MLOps per i Sistemi Multi-Agente
Portare un sistema multi-agente in produzione introduce complessita che un singolo LLM non ha. Non basta loggare l'output finale; serve visibilita a livello di agente.
Le metriche critiche sono:
- Task completion rate: % di CAD che generano G-code valido al primo tentativo
- Hallucination rate per agente: il Coder genera G-code sintattico invalido? Il Checker marca falsi positivi su fattibilita?
- Latenza end-to-end: tempo totale dal CAD al G-code pronto per la macchina
- Cost per richiesta: somma dei token usati da tutti e quattro gli agenti
Ogni agente ha il suo profilo di costo. Un'analisi CV del Checker costa CPU; una generazione iterativa del Coder costa token. Se il budget totale e stretto, dovete monitorare dove va la spesa.
Per il debugging, servono log strutturati:
{
"request_id": "req_2024_001",
"timestamp": "2024-01-15T10:32:44Z",
"agents": {
"charter": {
"status": "success",
"duration_ms": 450,
"output": { "specifications": [...] }
},
"checker": {
"status": "warning",
"duration_ms": 2100,
"flags": ["geometry_tolerance_tight", "edge_sharpness_high"],
"feasibility_score": 0.68
},
"tooler": {
"status": "success",
"duration_ms": 280,
"output": { "tools": [...], "params": [...] }
},
"coder": {
"status": "failed_iteration",
"attempts": 3,
"final_status": "success",
"duration_ms": 1800
}
},
"total_duration_ms": 4630,
"tokens_used": 3450,
"cost_usd": 0.0052
}
Questi log permettono di identificare colli di bottiglia: Se il Checker fa timeout regolarmente, sapete dove ottimizzare. Se il Coder fallisce spesso su certe geometrie, potete raccogliere dati di training.
Il versioning in un sistema multi-agente non puo essere monolitico. Non versionate "il sistema" come v1.0. Versionate:
- Prompt di ogni agente (es.
charter_prompt_v2.3) - Tool (es.
cv_analyzer@1.2.4) - Modello usato (es.
llama-2-70b-instructvsmistral-8b) - Configurazione di fallback e timeout
Un sistema di run tracking deve registrare quale versione di ogni componente e stata usata in ogni richiesta. Cosi se vedete un drop in accuracy, potete risalire a quale cambio l'ha causato.
Per i costi, un'architettura multi-agente puo sembrare piu cara (quattro modelli invece di uno) ma il valore emerge dal confronto. Su migliaia di richieste, il Checker che filtra disegni non fattibili prima del Coder vi fa risparmiare latenza e token. Il Tooler che seleziona parametri ottimali riduce il numero di iterazioni del Coder. La decomposizione non e un costo, e un investimento in efficienza.
FAQ
Qual è la differenza tra un agente AI e una semplice chiamata API a un LLM?
Una chiamata API a un LLM e una transazione reattiva e stateless: mandate un prompt, ricevete un output, fine. Un agente AI e un sistema autonomo che mantiene uno stato (cosa ho gia fatto, cosa devo fare), persegue un obiettivo, e decide autonomamente se usare tool (API, database, codice, sensori) per progredire verso l'obiettivo. L'agente orchestra le capacita del modello; non si limita a interrogarlo. Nel caso di MachinaCheck, il Charter non e una semplice chiamata API: e un agente che mantiene il contesto della specifica, valuta se ha abbastanza informazioni, e decide se chiedere al Checker di procedere o se ha bisogno di dati aggiuntivi dall'operatore.
Come si valuta la performance di un sistema multi-agente?
Non si misura l'accuratezza dei singoli agenti in isolamento. Si misura il successo del task end-to-end: il CAD e stato trasformato in G-code valido e eseguibile? I metriche chiave sono il task completion rate (% di richieste con output utilizzabile), l'efficienza (costo totale in token, latenza), e la robustezza (il sistema fallisce gracefully o crasha su input imprevisti?). Spesso servono evaluation harness custom che simulino scenari operativi reali: file CAD complessi, geometrie edge-case, vincoli di tolleranza stringenti. I benchmark generici non bastano.
È possibile costruire sistemi multi-agente efficaci con modelli open-source?
Assolutamente. Modelli open-source come Llama 3 o Mistral sono eccellenti per agenti specializzati, soprattutto se fine-tuned su dati di dominio. Un Checker specializzato in geometria manifatturiera con fine-tuning su 500 esempi di disegni reali supera un modello generico grande. Questo approccio vi da controllo completo (no vendor lock-in con OpenAI o Anthropic), privacy (i vostri dati rimangono on-premise), e efficienza di costo (un modello 8B su GPU costa meno di API proprietarie a volume alto). Per applicazioni enterprise B2B dove il valore risiede nella specializzazione, gli open-source sono spesso la scelta giusta.
Se affrontate un problema simile — workflow complessi che richiedono reasoning su piu step, task dove l'isolamento dei difetti conta, sistemi che devono stare in produzione e rimanere manutenibili — un'architettura multi-agente potrebbe essere la risposta. Discussioni piu approfondite su trade-off architetturali e specifiche implementative: il team di Jungletech e disponibile.